Backup is performed automatically based on the defined schedule during initial setup. In this version the schedule is per cluster and therefore when the scheduled time comes up and the backup is initiated, the backup is done on all available volumes.
The backup process is based on snapshots that are taken shortly after the backup schedule comes up, and then a backup of the data based on the snapshot is copied to S3 (changed block ranges since the last backup). For example there could be a daily schedule at 1:00 am, at which time the backup procedure will start and take a snapshot on each of the existing available volumes. Once snapshots are taken, the backup exporter will start the backup procedure for each of the volumes. It will create a temporary clone of the snapshot and copy the data to S3.
This ensures that only data present on the volume during the backup scheduled time when the snapshot was taken will be backed up, and that we have time consistency for the backup. The cloned volumes are temporary and will be deleted once the backup is finished.
The first backup of a volume will always be a full backup. From this point on every backup of the volume will be incremental and will copy and store only the changed block ranges. During the backup process the exporter will run a comparison of the existing snapshot to the previous backup snapshot to identify the block ranges that were changed. Only the changed block ranges will be copied during the incremental backup.
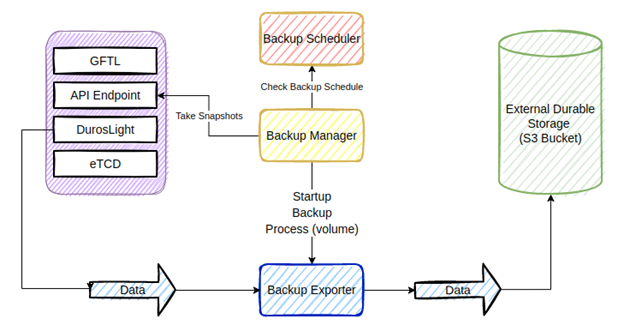
Only available volumes will be backed up to S3, and therefore snapshots that are not associated to a volume will not be backed up. The same is true for volumes that were not available during the backup time.