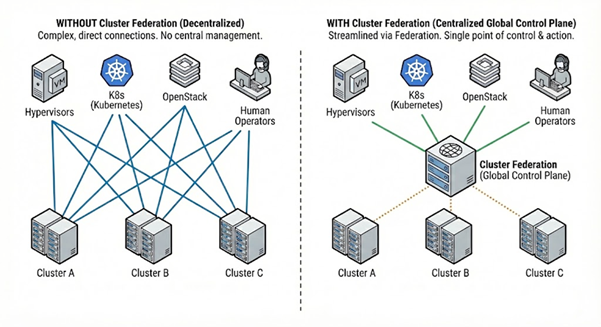
Cluster Federation (CF) is a multi-cluster management control plane designed to overcome the inherent scale limitations of single Lightbits storage clusters. CF acts as a provisioning broker across multiple attached Lightbits clusters, enabling users to scale their storage infrastructure quickly and simply. The primary value of this centralized system is to provide a unified interface for centralized fleet-wide management, which is intended to ensure seamless integration with existing deployments and the goal of requiring no or minimal changes to current API usage.
For its initial release (V1), Cluster Federation supports complete Create, Read, Update, Delete (CRUD) operations for managing volumes and snapshots across the federation.
The current version is delivered as a set of container images and is deployed using a dedicated script that simplifies the installation. This initial setup provides a single, fault-tolerant service that ensures persistent configurations, enabling the service to retain data following restarts and upgrades. High Availability (HA) via Kubernetes (K8s) and Helm for true resilience and streamlined deployment (using StatefulSets, Services, and Valkey Sentinel) is planned to be added in the future, targeted for subsequent phases (Version 1.1 and beyond).
CF is also the strategic foundation for future intelligent cluster management, which will include extended policy-driven provisioning based on capabilities, geography, and operational status in later versions.
CF Key Concepts
Intelligent Placement Policy
CF employs intelligent policy-driven provisioning to automate storage allocation based on predefined rules. For V1.0, CF uses a simple placement policy: volumes are provisioned on the cluster according to the provisioned ratio of existing clusters. CF will always attempt to place a new volume on the cluster with the lowest provisioned ration (Provisioned Capacity/Available Capacity).
Data Consistency
CF maintains an in-memory cache (IMT) of volumes, snapshots, and cluster information. This data is regularly synced (polled) from the managed clusters. In addition, CF persistently stores information about the managed clusters. This information is saved to a file so that when CF is restarted, it will connect to these clusters, poll the data, and resume operation (fault-tolerant behavior).
CF V1 Functionality and Limitations
The CF V1 release is limited in scope and functionality to quickly deliver essential multi-cluster scaling capabilities. These limitations and architectural assumptions are summarized below.
Deployment package via Ansible playbook for a standalone service.
V1 supports a single project (defined by the customer). Multi-tenancy will be introduced in a later version.
Full CRUD operations exclusively for volumes and snapshots.
QoS/Labels: In V1, volume creation and update operations will not support flags for QoS Policy UUID/Name or volume labels.
Lists Filtering: List commands for volumes and snapshots will only support filtering options of snapshot/volume name or uuid.
Default placement policy: volumes are provisioned on the cluster with the lowest provisioned usage ratio (provisioned capacity/available capacity).
Volume Naming: CF assumes volume and snapshot names to be globally unique across all clusters (within the context of the supported single project in V1).
Monitoring is limited to basic health probing (as is in DMS). Future versions will include more observability capabilities.
CF V1 supports managing three-node clusters and above.
Up to two clusters are supported for v1.0.
Placement logic is eventually consistent and non blocking, such that placement decision is based on the last information polled from the cluster.