This article details various maintenance-related tips, best practices, and other information for effectively handling Lightbits servers.
This article is for advanced users. It requires a high level of knowledge of Lightbits server maintenance. For any additional questions, contact Lightbits Support.
Server Management Components and Responsibilities
This section discusses the management components and responsibilities of the Lightbits server.
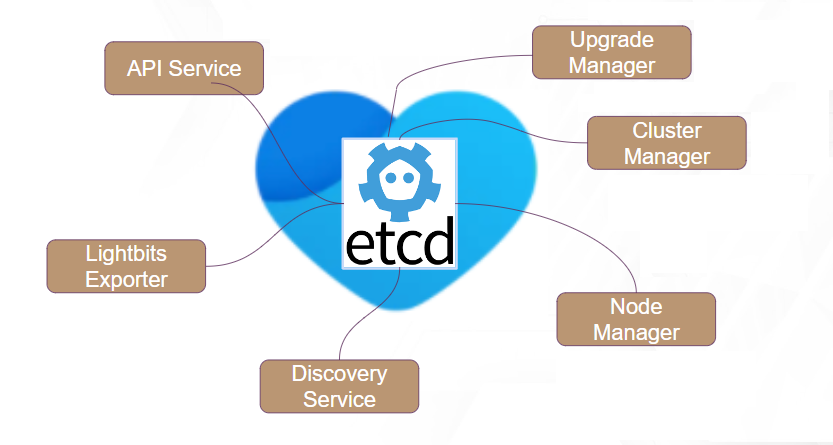
api-service
The ears of the system. Handles API (REST/gRPC) requests.
active-active, runs on all servers.
Asynchronous by design.
cluster-manager
The brain of the system. Handles cluster-wide operations (e.g., places volumes, decided to set nodes as active/inactive, triggers dynamic rebalancing).
active-passive, runs on all servers. Only one instance (“the leader”) is active.
node-manager
The arms of the system. Responsible for orchestrating the local services and resources, based on Cluster-Manager requests.
One instance per server.
lightbox-exporter
The mouth of the server. Exports the system metrics to Prometheus (also used for alerts/alarms).
One instance per server.
discovery-service
The eyes of the server. Keeps clients informed on how to connect to the cluster, and updates them when there are changes (for example, servers being added/removed from the cluster).
active-active, runs on all servers.
upgrade-manager
Cluster-wide mini service: active-passive, runs on all servers. Only one instance ("the leader") is active.
Orchestrates and runs Lightbits upgrades.
One local mini service to update local services.
Lightbits Services Startup Workflow
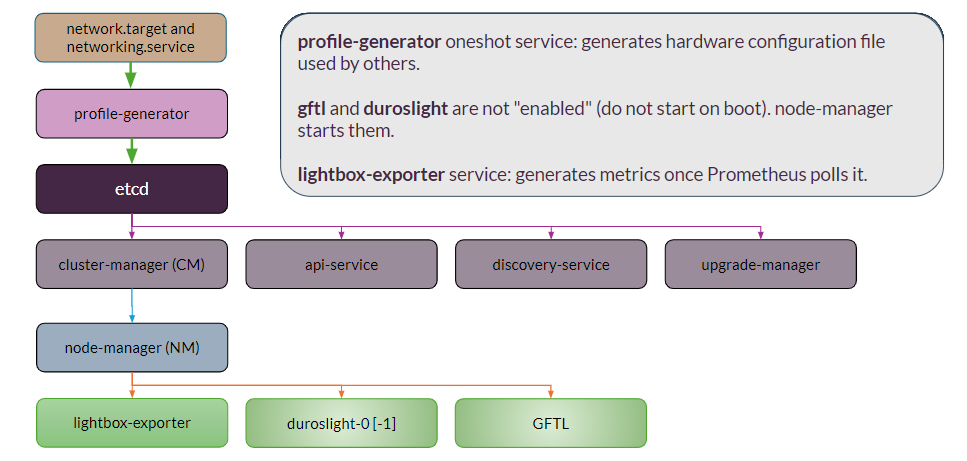
Lightbits services starts after network.target and networking.service are up.
profile-generator (PG): Service starts and exits (oneshot). Looks at hardware and generates configuration files for NM, DL, and GFTL. File:
/etc/profile-generator/system-profile.yaml.etcd: Third party clustered key value database starts up and connects with peers (decides on leader), and begins operating.
Starts in parallel after PG and etcd: api-service, discovery-service, upgrade-manager, and cluster-manager (CM). CM is the decision maker at the cluster level.
node-manager (NM): Reads ETCD and configurations generated by profile-generator, to configure and start GFTL and then Duroslight.
GFTL (Global Flash Translation Layer): Takes all SSDs and sees them as one logical layer. This also completes abrupt and graceful recoveries. Abrupt: Scans through all Flash to understand the state (note that this could take many hours). Graceful: Starts quickly as the state is already saved on the SSDs by a previous graceful shutdown.
duroslight service[s]: Started as duroslight-0. In dual numa, it also starts duroslight-1. Uses SSD over TCP protocol. All requests are sharded. All read and write requests are broken up into 128K chunks. For any given volume, the same CPU handles certain chunks. All requests from all clients are balanced across CPUs.
lightbox-exporter service: Generates metrics once Prometheus polls.
GFTL and Duroslight are not "enabled" (they do not start on boot). NM starts them.
States: Inactive → GFTL → Duroslight → Activating (connection to DL peers) → Active → volume rebuilds.
Lightbits Services Shutdown Sequence
During an abrupt shutdown, the system does not save the state. On boot, GFTL performs an abrupt recovery.
During a graceful shutdown, Duroslight is shut down first: It disconnects clients, and makes sure that any writes in progress are complete. - GFTL saves state information into ETCD and Flash array. Sync points for rebuilding are saved to ETCD. Other state information is saved to Flash array. - NM shuts down. - Remaining services are shut down.
Startup/Shutdown Order
The table below details the startup and shutdown order for the Lightbits Services server.
Lightbits Services Shutdown Order | Lightbits Services Startup Order |
|---|---|
api-service | profile-generator |
profile-generator | etcd |
node-manager | cluster-manager |
cluster-manager | node-manager |
discovery-service | discovery-service |
lightbox-exporter | lightbox-exporter |
upgrade-manager | upgrade-manager |
etcd | api-service |
Node Initialization Types
The following are the node initialization types and their causes and results.
Abrupt shutdown and abrupt recovery:
Caused by force kill NM or force reboot.
Slow powerup.
Graceful shutdown and abrupt recovery:
Caused by graceful stop and reboot.
Fast powerup.
Graceful stop NM takes time for it to save to GFTL state.
Starting NM happens instantly and starts the powerup procedure. It can be monitored via lbcli list nodes -o yaml or the NM log.
Common Software Services Issues
The chart below illustrates some of the common issues with Lightbits software services, as well as remediation steps for resolving them.
Issue/Task | Remediation Steps |
|---|---|
No output with
|
|
Consistency issue with lbcli output. |
|
A node is clearly "Inactive". |
|
Need to start/stop |
Note: Consult with Lightbits Support prior to performing this action. Note: Never restart/stop |
Do not restart/stop Cluster-managerwithout Lightbits approval. Do not restart/stop Node-manager without Lightbits approval (unless it is clearly inactive).
Services and Failure Results
The following chart details failure results and consequences of crashes/failures/stops or restarts on a Lightbits server.
Service | Failure Result | Recovery | Recovery Time | Restart Result | Restart Time |
|---|---|---|---|---|---|
etcd | Node inactive. | ||||
cluster-manager | |||||
api-service | No API access. | Manual | 0 | ||
upgrade-manager | Upgrade failed. | Manual | 0 | ||
discovery-service | N/A | ||||
profile-generator | N/A | ||||
lightbox-exporter | No metrics exported. | Manual | 0 | ||
node-manager | Node inactive. | Auto-revive | 20 minutes (1) | Node inactive. | 20 minutes |
duroslight | Node inactive. | Auto-revive | 20 minutes (1) | Node inactive. | 20 minutes (1) |
gftl | Node inactive. | Auto-revive | Up to 8 hours (2) | Node inactive. | Up to 8 hours (2) |