This article provides an analysis of the performance of a Lightbits disaggregated storage cluster in various scenarios. The primary focus is on volume failover times and node restart times - under both planned and abrupt conditions.
1. Volume Failover Time - Planned
In a planned scenario, the volume failover time is measured when the system is intentionally switched from one volume primary node to another. This is typically done for maintenance, upgrades, or other planned activities. The failover time is crucial, as it directly impacts the system's downtime and the user experience.
Time to serve traffic from a different node replica: 2sec
Notes on the NVMe/TCP ANA (Asymmetric Namespace Access) operation:
The driver maintains connectivity with all the nodes that carry its volumes' replicas.
The driver keeps connections with all the connections, but only the primary actively serves data while the paths are inaccessible.
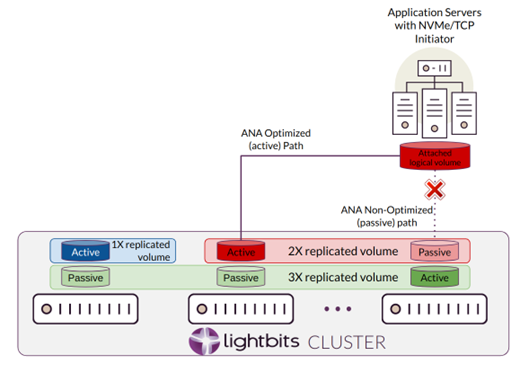
As the ANA path transition is designed, no I/O error is expected to get to the application layer, reads may be delayed, and writes may be buffered or delayed (depending if page cache is being used). The switchover time mentioned above should not affect application behavior.
2. Volume Failover Time - Unplanned
In contrast to the planned scenario, an abrupt volume failover occurs unexpectedly, often due to a system failure or other unforeseen events. The speed at which the system can recover and switch to a backup volume is critical in minimizing data loss and maintaining system availability.
Time to detect and serve traffic from a different node replica: up to 15sec
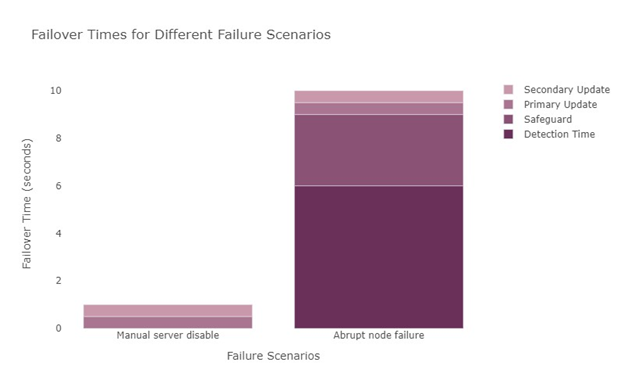
In this scenario, the total failover time is up to 10 seconds. The breakdown of the sequence is as follows:
Detection of heartbeat failure: up to 6 seconds
Safeguard: up to 3 seconds if the old primary cannot get notifications
Designating a new primary node: up to 0.5 seconds
Updating a secondary update: up to 0.5 seconds
The diagram below provides a visual representation of the different failure scenarios and their respective failover times.
3. Node Restart Overall - Planned
A planned node restart is a common occurrence in any storage system. This could be due to scheduled maintenance, system upgrades, or to rectify minor issues. The time it takes for a node to restart and become fully operational is a key performance indicator, as it directly impacts the overall system performance and availability.
Time to switch to active state after power cycle completion (assuming graceful shutdown): 10min
Time to recover all missing data after a power cycle from other replicas, when the node is already in Active state: capped by 4 TB/hour. This metric depends on the number of nodes in the cluster. Additional nodes with evenly spread volumes can reduce these metrics.
4. Node Restart Overall - Abrupt
An abrupt node restart is typically triggered by unexpected system errors or failures. The efficiency of the system's recovery mechanisms is tested during such events. The quicker a node can recover and restart, the less impact there will be on the system's performance and the user experience.
Time to switch to Active state after power cycle completion: 1h per 50TB per instance. Smaller sizes will (linearly) take less time.
Time to recover all missing data after the power cycle and becoming Active from replicas - same as in the planned case.
Specific (Measured) Optional Example
This is an example comparing two different deployments, and how rebuild time and permanent failures are affected.
3 clusters, 10 servers each (30) | |
Overall utilized capacity (example) | 600 TB (1.8PB with a replication factor of 3) |
Usable capacity per server (before replication) | 150 TB |
Estimated rebuild throughput (all clusters) | 12 TB/hr (3 clusters, 4 TB/hr each) |
Utilized capacity per server | 60 TB (600 TB x 3 rep factor / 30 servers) |
Single server rebuild time | 15 hrs |
Utilized capacity per rack | 180 TB (3 servers x 600 TB x 3 rep factor / 30 servers) |
Rack rebuild time | 15 hrs |
Maximum usable capacity (Rep. Factor 3) | 1500 TB |
Rebuild throughput can vary, depending on hardware configuration, number of Lightbits software instances and workloads.